Ostatnio opisywałem kilka nowości, które weszły do języka Python wraz z wersją 3.9. Następstwem tego wpisu były pytania o to, która wersja Pythona jest najlepsza. Której wersji języka zalecam używać. Czy najnowsza jest najlepsza? A może stosować, którąś ze starszych? Odpowiedź na te i inne pytania znajdziecie w dzisiejszym artykule.
Na początku października nakładem wydawnictwa CiscoPress została wydana książka Cisco Certified DevNet Associate DEVASC 200-901 Official Certification Guide. Na tą książkę czeka wiele osób, które mają w planach przystąpienie do egzaminu. Zainteresowane nią są też osoby, które po prostu chcą poznać świat DevNet. Pożyczyłem książkę na kilka godzin od znajomego, dzięki temu mogę wam przedstawić jej recenzję.
W krótkim artykule opisującym nowości w języku Python w wydaniu 3.9 zwróciłem uwagę na dwa operatory pozwalające na operowanie na zmiennych typu słownikowego (dict). W dzisiejszym wpisie w ramach Wtorków z Pythonem pokażę Ci kilka sposobów na łączenie dwóch lub więcej zmiennych słownikowych ze sobą. Pisząc swoje programy do automatyzacji bardzo często będziesz te operacje wykonywać.
Metoda update()
W dzisiejszym artykule posługiwać będę się trzema zmiennymi słownikowymi. Zdefiniuje je w poniższy sposób. Zauważmy, że zarówno w zmiennej x jaki i z występuje klucz ‘a’, lecz ma przypisane inne wartości.
>>> x = {'a': 1, 'b': 2}
>>> y = {'c': 3, 'd': 4}
>>> z = {'a': 5, 'f': 6}
Pierwsza metoda łączenia ze sobą dwóch zmiennych typu słownikowego polega na wykorzystaniu metody update(). Gdy wywołamy ją jako metodę zmiennej x jako argument podając zmienną y, to zawartość zmiennej y zostanie doklejona do zmiennej x.
W przypadku, gdy nazwy kluczy się powtarzają, wartość klucza w zmiennej, dla której metoda jest uaktualniana zostanie zaktualizowana
>>> x.update(z)
>>> x
{'a': 5, 'b': 2, 'f': 6}
Dlatego ważne jest by dokładnie rozumieć kierunek działania metody update(). Wywołanie jej ze zmiennej z przyniosłoby następujący efekt.
>>> z.update(x)
>>> z
{'a': 1, 'f': 6, 'b': 2}
Łączenie zmiennych operatorami **
Bliźniaczo podobna do powyższej jest metoda operatorów **. Wymaga ona jednak zapisania wyniku operacji w trzeciej zmiennej. Nie modyfikuje ona żadnej ze zmiennych, które łączymy jak to miało miejsce w poprzednim przykładzie. Została ona wprowadzona w wydaniu 3.5 języka Python. Nie jest ona zbyt intuicyjna w swoim zapisie i niewielu programistów z niej korzystało.
>>> u = { **x, **y}
>>> u
{'a': 1, 'b': 2, 'c': 3, 'd': 4}
>>> w = { **x, **z}
>>> w
{'a': 5, 'b': 2, 'f': 6}
Jak widać w przypadku powtarzających się kluczy nadpisana zostanie wartość tego z lewej strony. Zaletą tej metody jest jednak to, że w pojedynczym zapisie możemy połączyć ze sobą wiele zmiennych słownikowych. Operacje łączenia wykonują się od lewej do prawej.
>>> t = { **x, **y, **z}
>>> t
{'a': 5, 'b': 2, 'c': 3, 'd': 4, 'f': 6}
Połączyć dwie zmienne słownikowe możemy jeszcze tworząc trzecią zmienną jawną deklaracją typu, czyli dict(x, **y). Metoda ta działa jednak jedynie w przypadku, gdy wszystkie klucze w słownikach są tekstem.
Operatory w Python 3.9
W Python 3.9 wprowadzono operacje na zmiennych słownikowych za pomocą operatorów union (|) oraz in-place union (|=). Pierwszy z nich jest odpowiednikiem zapisu {**x, **y}.
>>> x | y
{'a': 1, 'b': 2, 'c': 3, 'd': 4}
>>> x | z
{'a': 5, 'b': 2, 'f': 6}
>>> x | y | z
{'a': 5, 'b': 2, 'c': 3, 'd': 4, 'f': 6}
Sam operator | nie modyfikuje wartości żadnej ze zmiennych. Wynik operacji możemy przypisać do nowej zmiennej. Inaczej zachowuje się operator |=, który połączoną wartość zapisuje w zmiennej po lewej stronie wywołania. Jest on zatem odpowiednikiem wywołania metody update().
>>> x |= y
>>> x
{'a': 1, 'b': 2, 'c': 3, 'd': 4}
>>> y
{'c': 3, 'd': 4}
Jak widzisz łączenie zmiennych słownikowych można wykonać na wiele sposobów. Wybierz odpowiedni dla swojego programu. Koniecznie pamiętaj, która metoda nadpisuje wartość jednej z łączonych zmiennych aby nie stracić przetwarzanych danych.
We wtorek oficjalnie wydano Python 3.9. Nowa wersja nie jest niczym przełomowym, mam wrażenie, że autorzy skupili się na bardziej na stabilizacji i uporządkowaniu kodu języka niż na wprowadzaniu nowych funkcjonalności. Poniżej krótka lista najważniejszych moim zdaniem zmian patrząc z perspektywy osoby zajmującej się automatyzacją infrastruktury IT.
Zmiany i nowości w Python 3.9
Poniżej moja subiektywna lista najciekawszych zmian w nowej wersji języka:
Wprowadzono dwie nowe operację na zmiennych typu słownikowego, które wykonamy za pomocą operatorów. są to operacja łączenia oraz aktualizacji
Dwie nowe metody wprowadzone do obiektów typu str pozwalające na usunięcie prefiksu albo sufiksu w ciągu znaków.
Nowy modułzoneinfo, który pozwala na zarządzanie strefami czasowymi zgodnie ze standardem IANA. Oznaczenia stref czasowych według standardu IANA to na przykład “Europe/Warsaw”.
Ujednolicenie błędu związanego z importowaniem bibliotek zależnych. Zawsze zwracany będzie błąd typu ImportError.
Generator losowych bajtów (nie mylić z generatorem losowych liczb, który już istnieje od dawna)
Warto też zauważyć, że zmienia się także cykl wydawania nowych wersji. Dotychczas nowe wersje były wydawane co 18 miesięcy. Od wydania 3.9 cykl ten został zmniejszony do 12 miesięcy. Oznacza to, że nowości możemy spodziewać się częściej niż dotychczas.
Błędy w oprogramowaniu wynikają bardzo często z błędów programistów. Z naszego niedopatrzenia, z tego, że nie przewidzieliśmy pewnych sytuacji czy zachowania użytkowników. Mogliśmy też zaniechać poprawnego sprawdzenia poprawności danych wejściowych. Przyczyn jest wiele. Dlatego ważne jest, abyśmy skanowali kod źródłowy naszego programu niezależnie od tego czy jest on kompilowany czy interpretowany. Bardzo mnie cieszy, że pod koniec września właściciele publicznych repozytoriów w serwisie GitHub uzyskali możliwość wykorzystania w swoim repozytorium darmowego skanera podatności CodeQL.
Czym jest CodeQL?
Skanowanie kodu to funkcja używana do analizowania kodu w repozytorium GitHub w celu znajdowania luk w zabezpieczeniach i błędów w kodowaniu. Takie błędy popełnia każdy programista i nie jest to nic dziwnego. Ważne jest by odpowiednio eliminować je ze swojego programu i doskonalić swój warsztat. Należy też unikać wykorzystywania bibliotek, w których zidentyfikowano podatności bezpieczeństwa.
W GitHub Marketplace dostępnych jest kilka skanerów, w większości płatnych. Od niedawna właściciele publicznych projektów mogą skorzystać z darmowego skanera CodeQL. Jeśli skanowanie kodu wykryje potencjalną lukę lub błąd w kodzie, GitHub wyświetli alert w repozytorium. Po naprawieniu kodu, który wywołał alert, usługa GitHub zamyka alert.
Darmowa usługa ma jednak swoje limity. W przypadku darmowego konta użytkownik ma do wykorzystania 2000 tak zwanych Action Minutes w każdym miesiącu. W zależności od tego jakie operacje wykonujemy stosowany jest odpowiedni mnożnik w stosunku do rzeczywistego czasu pracy modułu. Dla kodu wykonywanego na platformie Linux jest to 1, Windows 2, zaś MacOS to 10. Domyślny limit wydatków ustawiony jest na $0. Oznacza to, że gdy wyczerpie się nasza pula darmowych minut to zadania przestaną się wykonywać. Więcej informacji znajduje się w dokumentacji.
Jak włączyć CodeQL
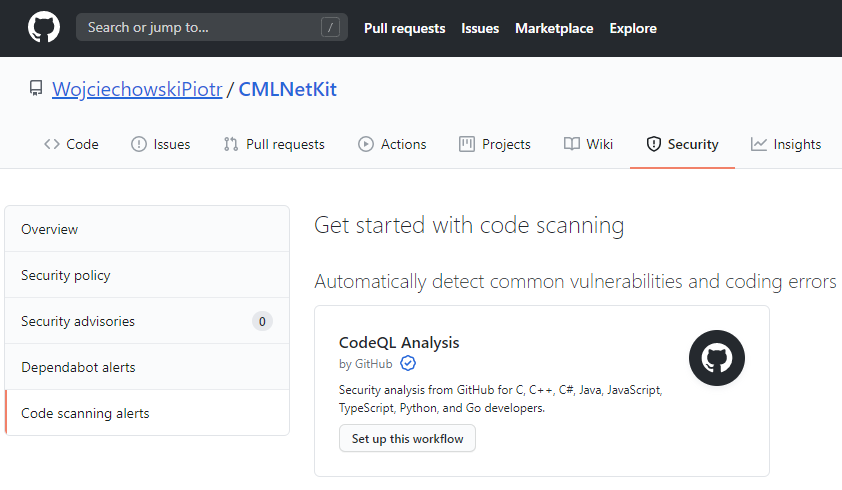
Włączenie skanera CodeQL jest bardzo proste. W głównym oknie naszego projektu przechodzimy do zakładki Security, a następnie z menu wybieramy sekcję Overview, oraz odnajdujemy przycisk Set up code scanning.
Aktywacja skanera kodu CodeQL w projekcie na GitHub
Dostępnych skanerów jest kilka, pamiętajmy jednak, że w większości są to produkty komercyjne, za których używanie będziemy musieli zapłacić. Wybieramy zatem z dostępnych opcji CodeQL.
Z dostępnych skanerów wybieramy CodeQL
Kreator doda w w naszym projekcie nowy plik codeql-analysis.yml. Znajduje się w nim konfiguracja skanera opisana w języku YAML. Otworzy się też nam edytor tego pliku co pozwoli nam już na tym etapie ustawić opcje skanowania. Zwróć w niej uwagę na sekcję on.
on:
push:
branches: [master]
pull_request:
# The branches below must be a subset of the branches above
branches: [master]
schedule:
- cron: '0 1 * * 3'
W moim projekcie CMLNetKit jest tylko jeden branch o nazwie master. W przyszłości, gdy projekt się rozrośnie, będzie ich więcej. Wtedy w sekcji on będę musiał zdefiniować, dla których gałęzi projektu skaner ma być aktywny.
Skanowanie definiujemy dla operacji push, pull oraz jako cykliczne zadanie crona.
Większości użytkowników powinny wystarczyć domyślne ustawienia skanera. Zainteresowani opisem wszystkich dostępnych opcji mogą zapoznać się z dokumentacją.
Wgranie pliku konfiguracyjnego CodeQL do repozytorium projektu
Działanie skanera w praktyce
Jeżeli zastosujemy domyślne ustawienia skaner będzie się uruchamiał domyślnie po kazdej aktualizacji kodu w repozytorium, czyli także od razu po dodaniu pliku konfiguracyjnego. Jego działanie jest sygnalizowane pomarańczową kropką status. Gdy na nią klikniemy, zobaczymy informację, że odbywa się w tle zdefiniowane przez nas zadanie.
Wykonywania zadania typu workflow w tle
Możemy teraz kliknąć na szczegóły i prześledzić działanie samego skanera. Jest ono podzielone na kilka etapów. Szczegóły wykonanej pracy w każdym z nich zobaczymy rozwijając właściwe poddrzewo z dostępnej listy.
Szczegóły działania procesu skanowania kodu przez CodeQL
Jeżeli w kodzie nie zostały znalezione żadne znane podatności, to status wykonania zadań w projekcie zmieni się na zielony
Sygnalizacja poprawnego wykonania zadań w projekcie
Jeżeli chcemy zobaczyć wyniki przeprowadzonych skanów musimy przejść do zakładki Actions, w której znajdziemy raporty z wykonanych skanów.