Jeżeli w Twoim domowym labie ląduje serwer Cisco UCS, to być może nie chcesz by działał 24/7. Prąd jest drogi, szumi to niemiłosiernie i jak nie masz serwerowni w garażu to po paru dniach będziesz miał dość odgłosów serwerowni w swoim domu. Z drugiej strony leń siedzi w każdym z nas i nikomu nie chce się chodzić by tylko kliknąć przycisk by uruchomić serwer. Zatem najbardziej przydatny skrypt to ten, który pozwoli uruchomić serwer zdalnie.
Co prawda Python 3.11 wyszedł w październiku zeszłego roku to dopiero niedawno miałem czas przyjrzeć się nowościom i zmianom w tej wersji języka. Nie ma ich co prawda bardzo dużo, ale niektóre wydają się dość ciekawe i do zastosowania nie tylko przez zaawansowanych programistów. Sam jako domyślny język używam od wielu miesięcy wersji 3.10, którą uważam za stabilną. Spójrzmy zatem co przynosi wersja 3.11.
W zeszłym tygodniu, 25 marca, w ramach eventu AdminDays miałem przyjemność poprowadzić warsztaty/prezentację związaną z automatyzacją w środowisku sieciowym. W czasie spotkania pokazałem proces tworzenia skryptu w języku Python, który wykonuje proste czynności administracyjne związane z odczytaniem i rekonfiguracją interfejsu Loopback. Z samym urządzeniem połączenie następuje za pomocą protokołu RESTCONF, a jeżeli ten jest niedostępny to za pomocą SSH z wykorzystaniem biblioteki Netmiko. Skrypt, wraz z zestawem linków do podstawowych bibliotek, które każdy programista sieciowy powinien znać, znajduje się w repozytorium GitHub Szkoły DevNet.
Jak w każdym języku programowania także w Pythonie znajdziemy ciekawe i zastanawiające konstrukcje składni. Na przykład dziwnie wyglądające *args i **kwargs w języku Python. Dziś pokażę Ci w jaki sposób poradzić sobie w sytuacji, gdy wywołujemy funkcję, ale nie wiemy ile argumentów do niej zostanie przekazanych. Z taką sytuacją w świecie automatyzacji infrastruktury mamy do czynienia dość często. Rozwiązanie w tym przypadku jest banalnie proste.
Wiele osób zaczynających swoją przygodę z Pythonem jest zafascynowana elastycznością tego języka oraz składnią, która jest dość intuicyjna. Następnie zderzają się z problemem, że za bardzo chcieliby upraszczać, a co za tym idzie nie do końca poprawnie stosują różne operatory. Chyba najczęściej mylnie używane są operatory porównania == oraz is.
Gdy programujemy skrypty związaną z contact center, czy innymi aplikacjami z rodziny telefonii IP, bardzo szybko spotkamy się zadaniami, w których musimy przetworzyć numery telefonów. Z produktów związanych z telefonią numer uzyskujemy zazwyczaj w formacie E.164. Dane zapisane w różnego rodzaju bazach danych czy plikach tekstowych, które nasze skrypty będą przetwarzać, prawie na pewno nie będą zawsze zgodne z tym międzynarodowym standardem. Z takim problemem miałem do czynienia niedawno, gdy w projekcie dla mojego klienta pisałem dodatkowe skrypty do Amazon Connect, czyli call center w chmurze Amazona. W operowaniu różnego rodzaju formatami numerów telefonicznych pomogła mi biblioteka phonenumbers.
Na pewno nie umknęło Twojej uwadze, że w języku Python nazwy niektórych obiektów, zmiennych czy funkcji składają się z podkreśleń umieszczanych na początku, na końcu lub po obu stronach. Jest to celowy zabieg, konwencja i standard, który ma na celu uporządkowanie kodu zarówno pod względem semantycznym, funkcjonalnym jak i optycznym, czyli ułatwić jego czytanie. W dzisiejszym artykule wyjaśnię Ci jakie znaczenie mają podkreślenia w tych konkretnych przypadkach.
Ostatnio opisywałem kilka nowości, które weszły do języka Python wraz z wersją 3.9. Następstwem tego wpisu były pytania o to, która wersja Pythona jest najlepsza. Której wersji języka zalecam używać. Czy najnowsza jest najlepsza? A może stosować, którąś ze starszych? Odpowiedź na te i inne pytania znajdziecie w dzisiejszym artykule.
W krótkim artykule opisującym nowości w języku Python w wydaniu 3.9 zwróciłem uwagę na dwa operatory pozwalające na operowanie na zmiennych typu słownikowego (dict). W dzisiejszym wpisie w ramach Wtorków z Pythonem pokażę Ci kilka sposobów na łączenie dwóch lub więcej zmiennych słownikowych ze sobą. Pisząc swoje programy do automatyzacji bardzo często będziesz te operacje wykonywać.
Metoda update()
W dzisiejszym artykule posługiwać będę się trzema zmiennymi słownikowymi. Zdefiniuje je w poniższy sposób. Zauważmy, że zarówno w zmiennej x jaki i z występuje klucz ’a’, lecz ma przypisane inne wartości.
>>> x = {'a': 1, 'b': 2}
>>> y = {'c': 3, 'd': 4}
>>> z = {'a': 5, 'f': 6}
Pierwsza metoda łączenia ze sobą dwóch zmiennych typu słownikowego polega na wykorzystaniu metody update(). Gdy wywołamy ją jako metodę zmiennej x jako argument podając zmienną y, to zawartość zmiennej y zostanie doklejona do zmiennej x.
W przypadku, gdy nazwy kluczy się powtarzają, wartość klucza w zmiennej, dla której metoda jest uaktualniana zostanie zaktualizowana
>>> x.update(z)
>>> x
{'a': 5, 'b': 2, 'f': 6}
Dlatego ważne jest by dokładnie rozumieć kierunek działania metody update(). Wywołanie jej ze zmiennej z przyniosłoby następujący efekt.
>>> z.update(x)
>>> z
{'a': 1, 'f': 6, 'b': 2}
Łączenie zmiennych operatorami **
Bliźniaczo podobna do powyższej jest metoda operatorów **. Wymaga ona jednak zapisania wyniku operacji w trzeciej zmiennej. Nie modyfikuje ona żadnej ze zmiennych, które łączymy jak to miało miejsce w poprzednim przykładzie. Została ona wprowadzona w wydaniu 3.5 języka Python. Nie jest ona zbyt intuicyjna w swoim zapisie i niewielu programistów z niej korzystało.
>>> u = { **x, **y}
>>> u
{'a': 1, 'b': 2, 'c': 3, 'd': 4}
>>> w = { **x, **z}
>>> w
{'a': 5, 'b': 2, 'f': 6}
Jak widać w przypadku powtarzających się kluczy nadpisana zostanie wartość tego z lewej strony. Zaletą tej metody jest jednak to, że w pojedynczym zapisie możemy połączyć ze sobą wiele zmiennych słownikowych. Operacje łączenia wykonują się od lewej do prawej.
>>> t = { **x, **y, **z}
>>> t
{'a': 5, 'b': 2, 'c': 3, 'd': 4, 'f': 6}
Połączyć dwie zmienne słownikowe możemy jeszcze tworząc trzecią zmienną jawną deklaracją typu, czyli dict(x, **y). Metoda ta działa jednak jedynie w przypadku, gdy wszystkie klucze w słownikach są tekstem.
Operatory w Python 3.9
W Python 3.9 wprowadzono operacje na zmiennych słownikowych za pomocą operatorów union (|) oraz in-place union (|=). Pierwszy z nich jest odpowiednikiem zapisu {**x, **y}.
>>> x | y
{'a': 1, 'b': 2, 'c': 3, 'd': 4}
>>> x | z
{'a': 5, 'b': 2, 'f': 6}
>>> x | y | z
{'a': 5, 'b': 2, 'c': 3, 'd': 4, 'f': 6}
Sam operator | nie modyfikuje wartości żadnej ze zmiennych. Wynik operacji możemy przypisać do nowej zmiennej. Inaczej zachowuje się operator |=, który połączoną wartość zapisuje w zmiennej po lewej stronie wywołania. Jest on zatem odpowiednikiem wywołania metody update().
>>> x |= y
>>> x
{'a': 1, 'b': 2, 'c': 3, 'd': 4}
>>> y
{'c': 3, 'd': 4}
Jak widzisz łączenie zmiennych słownikowych można wykonać na wiele sposobów. Wybierz odpowiedni dla swojego programu. Koniecznie pamiętaj, która metoda nadpisuje wartość jednej z łączonych zmiennych aby nie stracić przetwarzanych danych.
Błędy w oprogramowaniu wynikają bardzo często z błędów programistów. Z naszego niedopatrzenia, z tego, że nie przewidzieliśmy pewnych sytuacji czy zachowania użytkowników. Mogliśmy też zaniechać poprawnego sprawdzenia poprawności danych wejściowych. Przyczyn jest wiele. Dlatego ważne jest, abyśmy skanowali kod źródłowy naszego programu niezależnie od tego czy jest on kompilowany czy interpretowany. Bardzo mnie cieszy, że pod koniec września właściciele publicznych repozytoriów w serwisie GitHub uzyskali możliwość wykorzystania w swoim repozytorium darmowego skanera podatności CodeQL.
Czym jest CodeQL?
Skanowanie kodu to funkcja używana do analizowania kodu w repozytorium GitHub w celu znajdowania luk w zabezpieczeniach i błędów w kodowaniu. Takie błędy popełnia każdy programista i nie jest to nic dziwnego. Ważne jest by odpowiednio eliminować je ze swojego programu i doskonalić swój warsztat. Należy też unikać wykorzystywania bibliotek, w których zidentyfikowano podatności bezpieczeństwa.
W GitHub Marketplace dostępnych jest kilka skanerów, w większości płatnych. Od niedawna właściciele publicznych projektów mogą skorzystać z darmowego skanera CodeQL. Jeśli skanowanie kodu wykryje potencjalną lukę lub błąd w kodzie, GitHub wyświetli alert w repozytorium. Po naprawieniu kodu, który wywołał alert, usługa GitHub zamyka alert.
Darmowa usługa ma jednak swoje limity. W przypadku darmowego konta użytkownik ma do wykorzystania 2000 tak zwanych Action Minutes w każdym miesiącu. W zależności od tego jakie operacje wykonujemy stosowany jest odpowiedni mnożnik w stosunku do rzeczywistego czasu pracy modułu. Dla kodu wykonywanego na platformie Linux jest to 1, Windows 2, zaś MacOS to 10. Domyślny limit wydatków ustawiony jest na $0. Oznacza to, że gdy wyczerpie się nasza pula darmowych minut to zadania przestaną się wykonywać. Więcej informacji znajduje się w dokumentacji.
Jak włączyć CodeQL
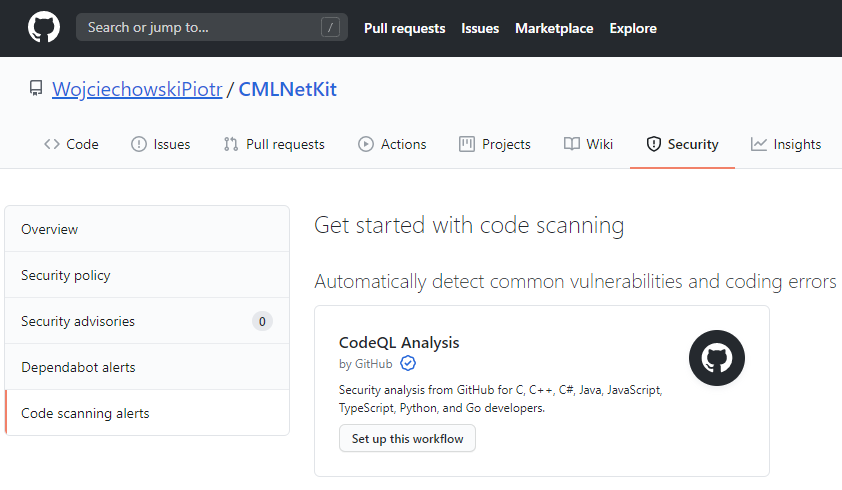
Włączenie skanera CodeQL jest bardzo proste. W głównym oknie naszego projektu przechodzimy do zakładki Security, a następnie z menu wybieramy sekcję Overview, oraz odnajdujemy przycisk Set up code scanning.
Aktywacja skanera kodu CodeQL w projekcie na GitHub
Dostępnych skanerów jest kilka, pamiętajmy jednak, że w większości są to produkty komercyjne, za których używanie będziemy musieli zapłacić. Wybieramy zatem z dostępnych opcji CodeQL.
Z dostępnych skanerów wybieramy CodeQL
Kreator doda w w naszym projekcie nowy plik codeql-analysis.yml. Znajduje się w nim konfiguracja skanera opisana w języku YAML. Otworzy się też nam edytor tego pliku co pozwoli nam już na tym etapie ustawić opcje skanowania. Zwróć w niej uwagę na sekcję on.
on:
push:
branches: [master]
pull_request:
# The branches below must be a subset of the branches above
branches: [master]
schedule:
- cron: '0 1 * * 3'
W moim projekcie CMLNetKit jest tylko jeden branch o nazwie master. W przyszłości, gdy projekt się rozrośnie, będzie ich więcej. Wtedy w sekcji on będę musiał zdefiniować, dla których gałęzi projektu skaner ma być aktywny.
Skanowanie definiujemy dla operacji push, pull oraz jako cykliczne zadanie crona.
Większości użytkowników powinny wystarczyć domyślne ustawienia skanera. Zainteresowani opisem wszystkich dostępnych opcji mogą zapoznać się z dokumentacją.
Wgranie pliku konfiguracyjnego CodeQL do repozytorium projektu
Działanie skanera w praktyce
Jeżeli zastosujemy domyślne ustawienia skaner będzie się uruchamiał domyślnie po kazdej aktualizacji kodu w repozytorium, czyli także od razu po dodaniu pliku konfiguracyjnego. Jego działanie jest sygnalizowane pomarańczową kropką status. Gdy na nią klikniemy, zobaczymy informację, że odbywa się w tle zdefiniowane przez nas zadanie.
Wykonywania zadania typu workflow w tle
Możemy teraz kliknąć na szczegóły i prześledzić działanie samego skanera. Jest ono podzielone na kilka etapów. Szczegóły wykonanej pracy w każdym z nich zobaczymy rozwijając właściwe poddrzewo z dostępnej listy.
Szczegóły działania procesu skanowania kodu przez CodeQL
Jeżeli w kodzie nie zostały znalezione żadne znane podatności, to status wykonania zadań w projekcie zmieni się na zielony
Sygnalizacja poprawnego wykonania zadań w projekcie
Jeżeli chcemy zobaczyć wyniki przeprowadzonych skanów musimy przejść do zakładki Actions, w której znajdziemy raporty z wykonanych skanów.