


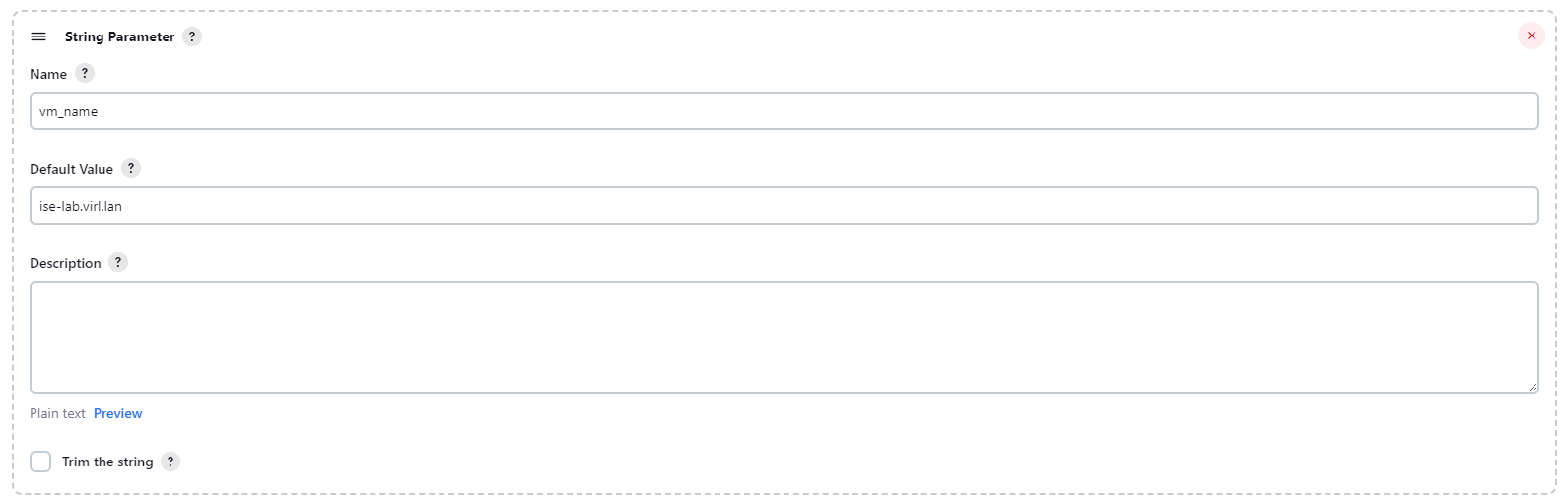

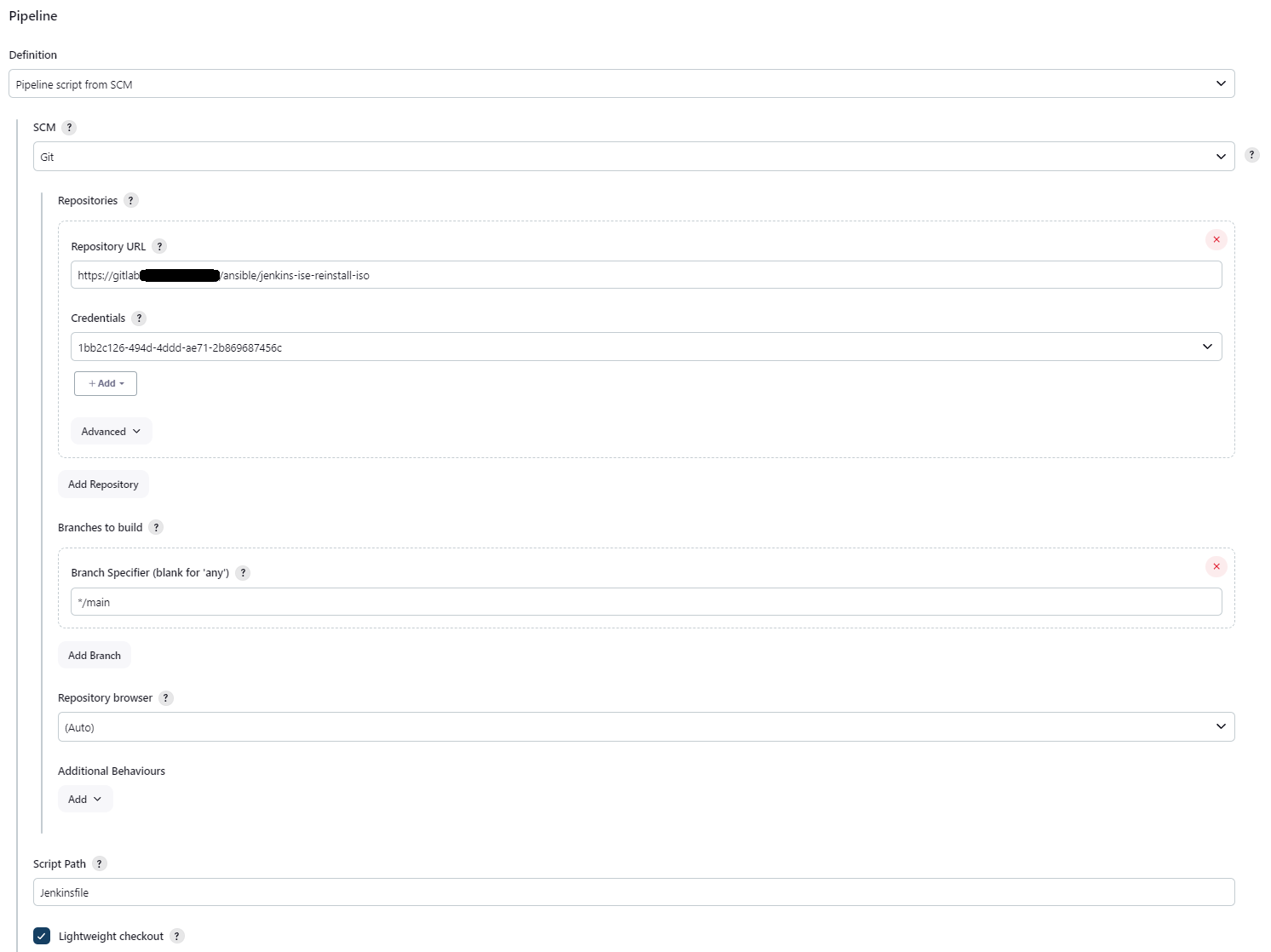


Gdy po reinstalacji za pomocą mechanizmy Zero Touch Provisioning maszyna wirtualna się uruchomi odtwarzamy z kopii zapasowej konfigurację Cisco ISE. Jest to o tyle proste, że w konfiguracji ZTP wskazaliśmy, że API Cisco ISE ma Dowiedz się więcej

Czy możemy uruchomić Cisco ISE i dokonać wstępnej konfiguracji bez dostępu do konsoli? Tak, służy do tego ZTP. Mechanizm Zero Touch Provisioning na Cisco ISE pozwala na przekazanie podstawowych parametrów konfiguracyjnych do nowej maszyny wirtualnej Dowiedz się więcej

W poprzednich dwóch krokach sprawdziłem warunki, czy w ogóle mogę odtworzyć Cisco ISE z kopii zapasowej. Sprawdziłem czy mam „świeżą” kopię zapasową oraz czas licencji trial jest bliski wyczerpania. Jeżeli oba warunki są spełnione to Dowiedz się więcej
